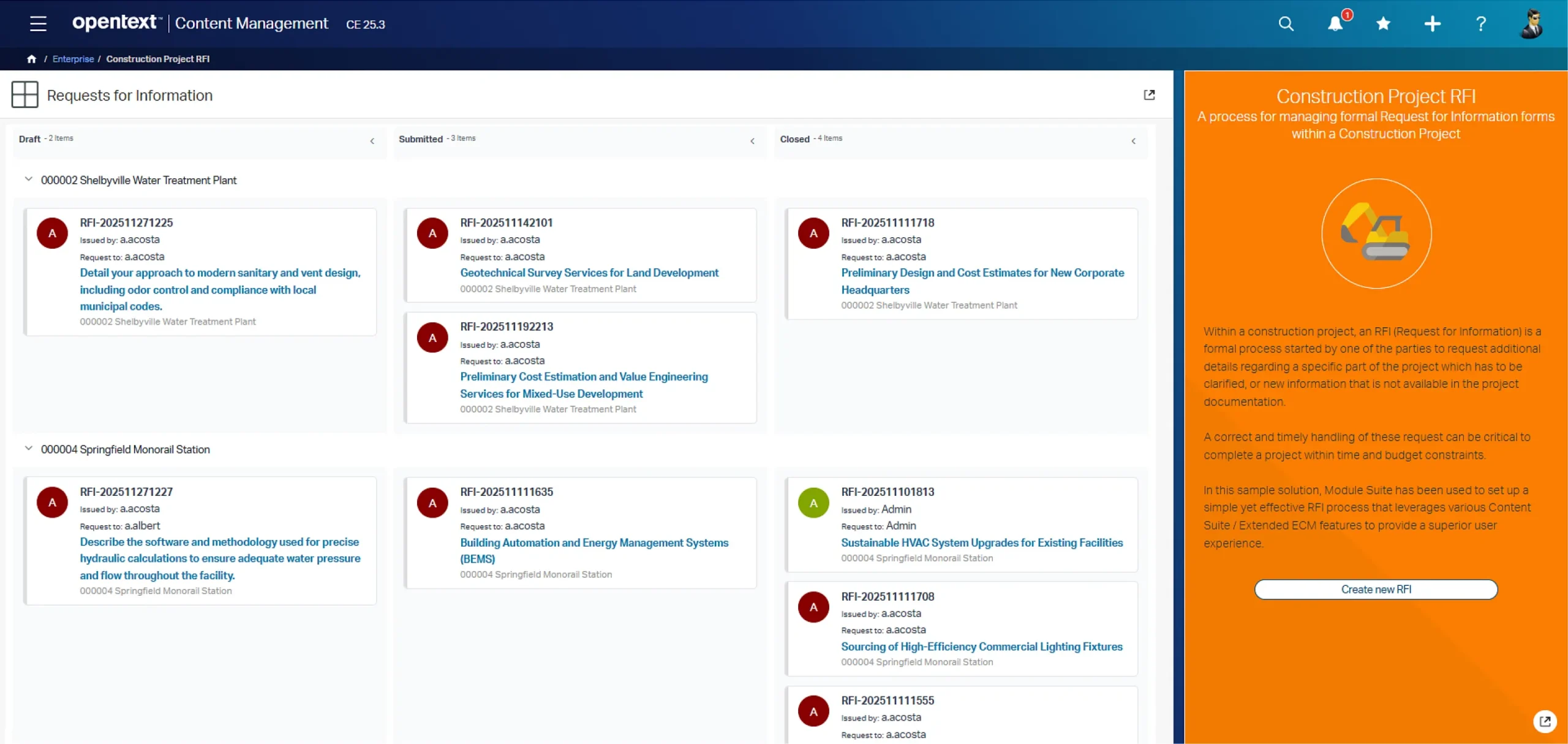
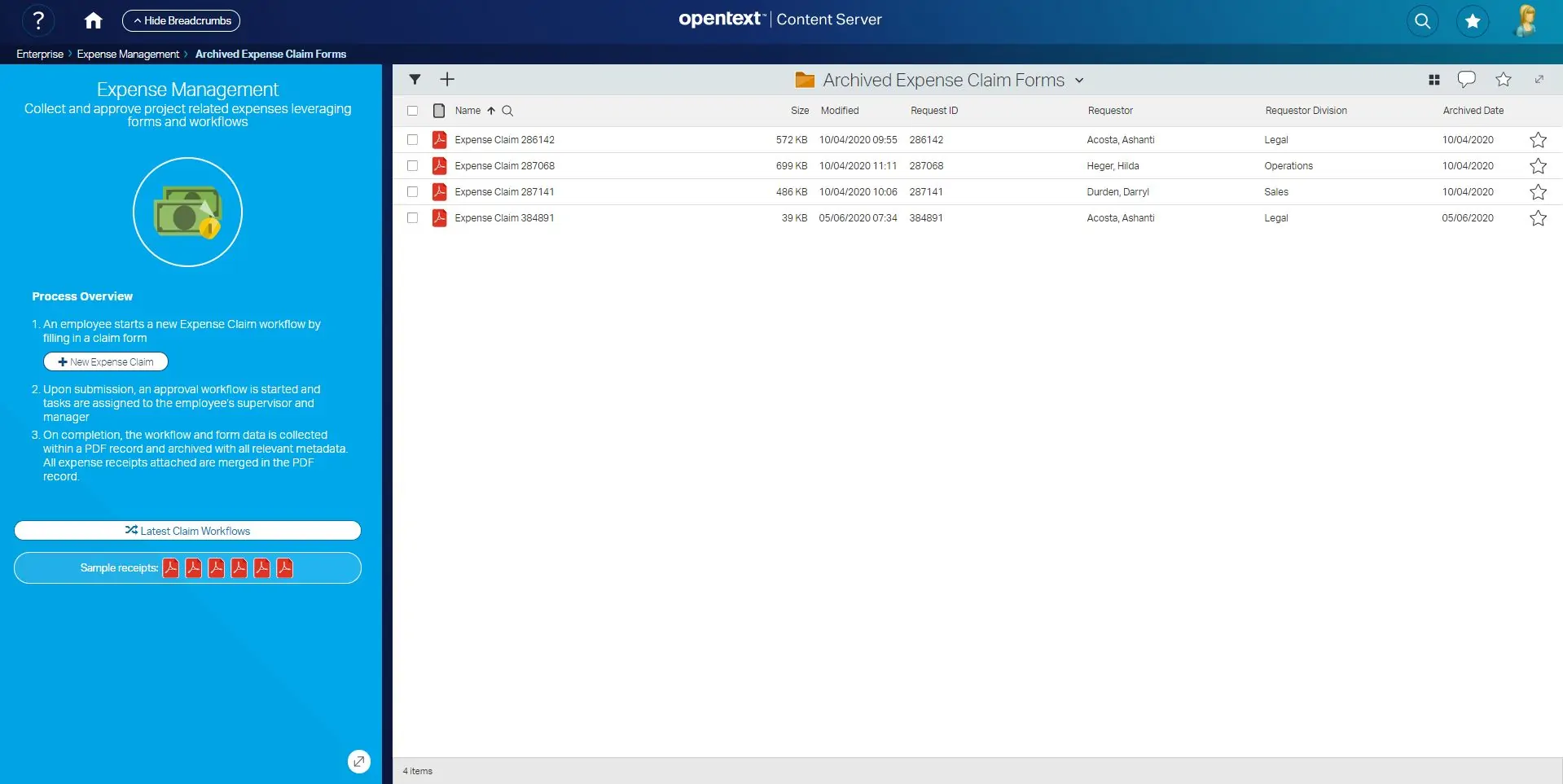
Let’s start from a Content Server container (in our case, a simple folder): a Content Script Callback has been set up to intercept the creation of new documents within this space. This means that any time one or more documents are dropped (or otherwise loaded) into the folder, the callback script is executed and the custom business logic applied to each object.