






Automating the initialization of all possible metadata for new documents ingested into a content repository is a critical feature that brings various benefits, including:
A possible, lightweight approach to the problem, described below, includes adding background listeners to the target repository containers. Once new documents are added, a tailored Content Script routing will apply all necessary rules to identify the documents, and generate or extract the required metadata.
There are numerous possible approaches to handle this need: the complexity can range from very simple tools to full-fledged management workflows for controlled documents.
The example shown here leverages spreadsheets and Content Script automation to obtain a simple yet powerful bulk metadata update solution.
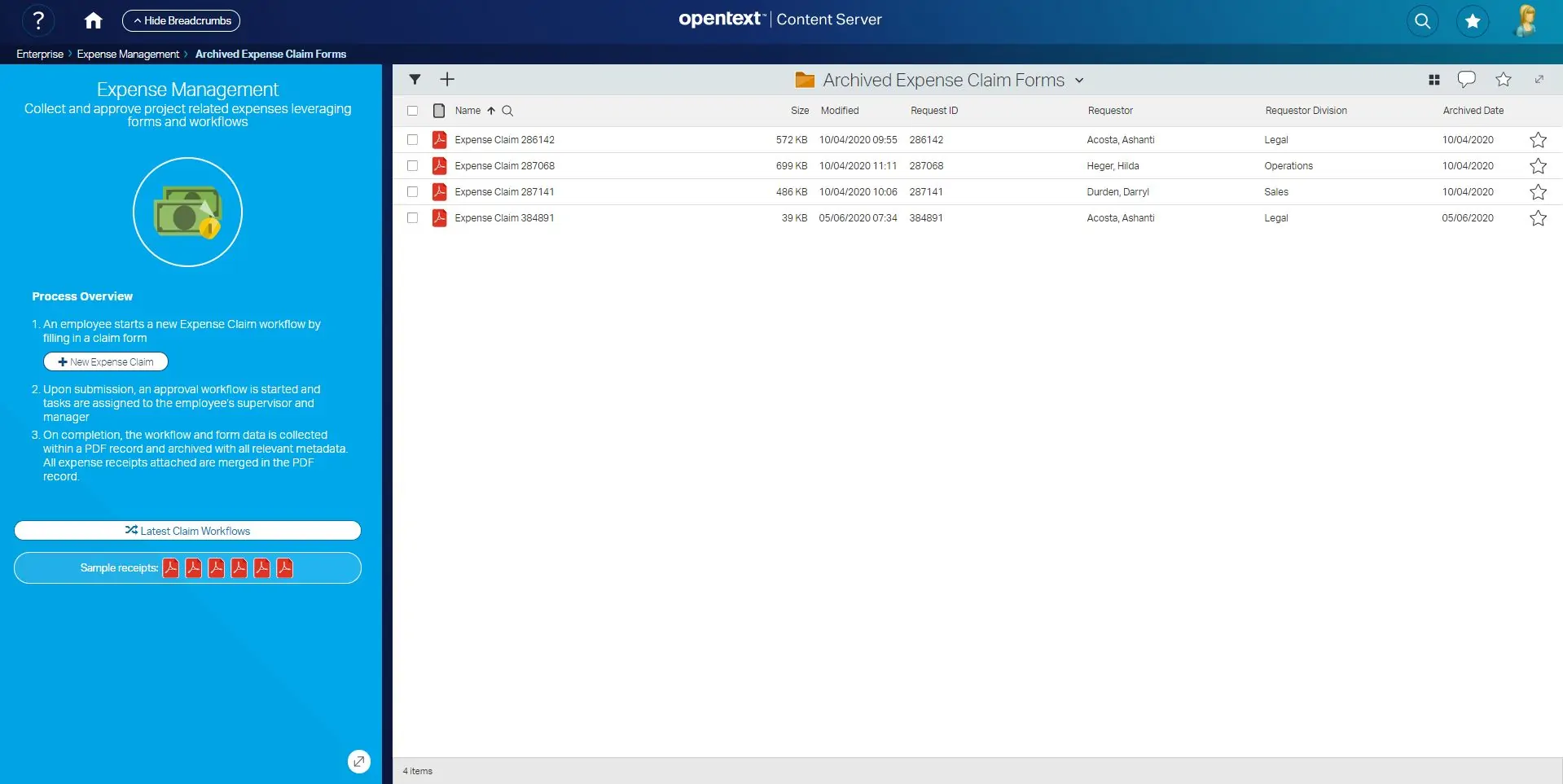
Let’s start from a Content Server container (in our case, a simple folder): a Content Script Callback has been set up to intercept the creation of new documents within this space. This means that any time one or more documents are dropped (or otherwise loaded) into the folder, the callback script is executed and the custom business logic applied to each object.
In our example, the callback script performs the following actions:
Specifically, the extraction of information from the document can be very powerful as there are many interesting possibilities, enabled by the variety of Content Script APIs available.
A basic operation can be to extract information from the file name. This could be done in a very straightforward way (e.g. use the file name as the document “Title”) or in a more creative way (e.g. extract an invoice ID based on a predefined pattern)
One step further could be to access properties specific to the type of document. For example, MS Word or Excel documents include a built-in “Title” and “Author” property. Content Script APIs include tools to access the files and read this data, as shown below.
A step further in terms of complexity could see you combining the integration and communication capabilities of Content Script with data available directly on the document. For example, once the invoice ID is identified by decoding the file name, an service call can be executed to fetch additional details from the ERP system.
In any case, once done, the new documents will be available within the store, and the processed metadata directly accessible.
Read more >
Read more >
Read more >
Valuable insights are the key to successful projects.
Be the first to hear about Module Suite’s latest features, news and releases
By clicking the “Sign up” button I declare that I have read and accepted the privacy policy.




Via Penate 4 – 6850
Mendrisio – Switzerland
+41 91 261 48 16
info@answermodules.com
© Copyright 2024. AnswerModules Sagl – OpenText is a trademark or registered trademark of the OpenText Corporation. Other trademarks, product names, brands and service names are properties of their respective owners.